背景
一天争取消化一篇文章。
11-30
- 标题:Information-Theoretic Exploration with Bayesian Optimization
- 作者单位:斯蒂文斯理工大学
- 会议: IROS 2016
问题定义
信息增益
\(H(m)=-\sum_{i} \sum_{j} p\left(m_{i, j}\right) \log p\left(m_{i, j}\right)\)
其中i 表示栅格的索引,而j表示栅格所有的可能的状态的索引。对于一个没有观测到的栅格,其概率为$p(m_{i, j}) = 0.5$
对于某个特定的C-space中的一点$x_i$而言,其所能得到的信息增益为 \(I\left(m, x_{i}\right)=H(m)-H\left(m \mid x_{i}\right)\)
其中$H(m)$为当前地图的信息增益,$H(m|x_i)$为给定在$x_i$处的观测后所期望的地图的信息增益。因此,该问题则变为找到C-space中的某一点$x^*$,使得信息增益最大
\[x^{*}=\underset{x_{i} \in \mathscr{G}_{\text {action}}}{\operatorname{argmax}} I\left(m, x_{i}\right)\]其中$\mathscr{G}_{\text{action}}$是的C-space的子集,是下一步可能去的地方。
Baysian Optimaztion
引用论文:《Gaussian Process Optimization in the Bandit Setting:No Regret and Experimental Design》
- Multi-armed bandit problem (多臂老虎机问题)
实际上是用高斯过程回归,取待测试的位置的一个子集来做高斯过程训练,然后用其余的位置来测试,得到剩余的位置的信息增益与协方差,然后评价函数为
\[x_{t}=\underset{x \in \mathscr{G}_{\text {action}}}{\operatorname{argmax}} \mu(x)+\beta \sigma(x)\]根据这个公式来算最佳位置。
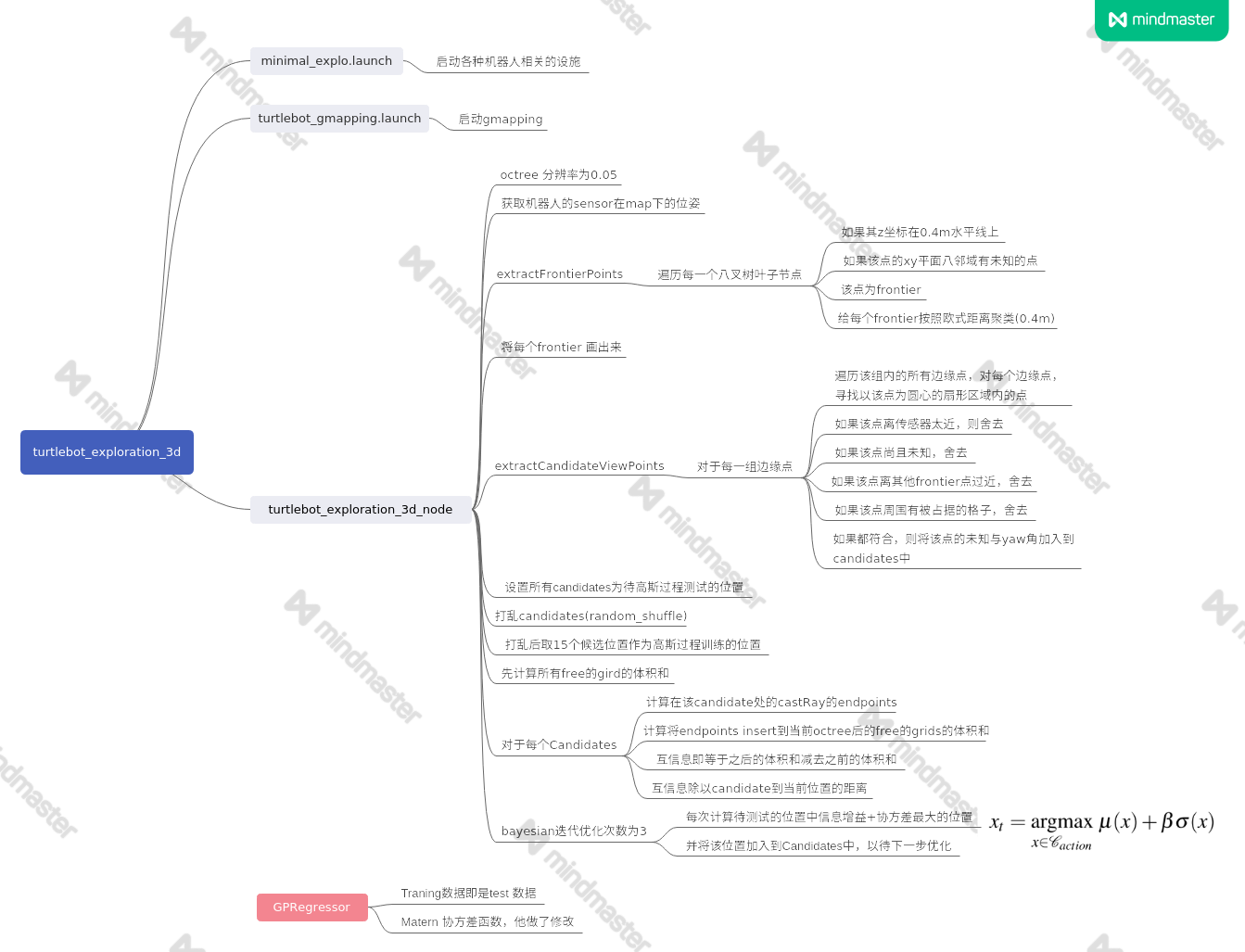
代码阅读
其代码在github: turtlebot_exploration_3d
我的阅读如下:
12-10
- 标题:Learn-to-Score: Efficient 3D Scene Exploration by Predicting View Utility
- 作者单位:ETHZ/Microsoft
- 会议: ECCV 2018
内容
World model
地图中的每个voxel存储两个值$M=(M^o, M^u)$,其中$M^o(v)$是该voxel的占据概率,$M^u(v)$是该voxel的不确定性。
当移动到一个新的地点$p$后,某个voxel的不确定性被更新为
\[M^u|p(v) = exp(-\eta)M^u(v)\]其中$\eta \in \mathbb{R} > 0$为 在p点处观测所带来的信息量。
Oracle utility function
用表面栅格(surface voxels)的不确定性来刻画地图:
\[ObsSurf(M) = \sum_{v\in Surf}(1-M^u(v))\]则某个位置$p$的得分函数可以刻画为
$s(M, p) = ObsSurf(M|p)-ObsSurf(M)
= \sum_{v\in surf}(1-exp(-\eta))M^u(v)
$
Learning the utility function
Multi-scale map representation
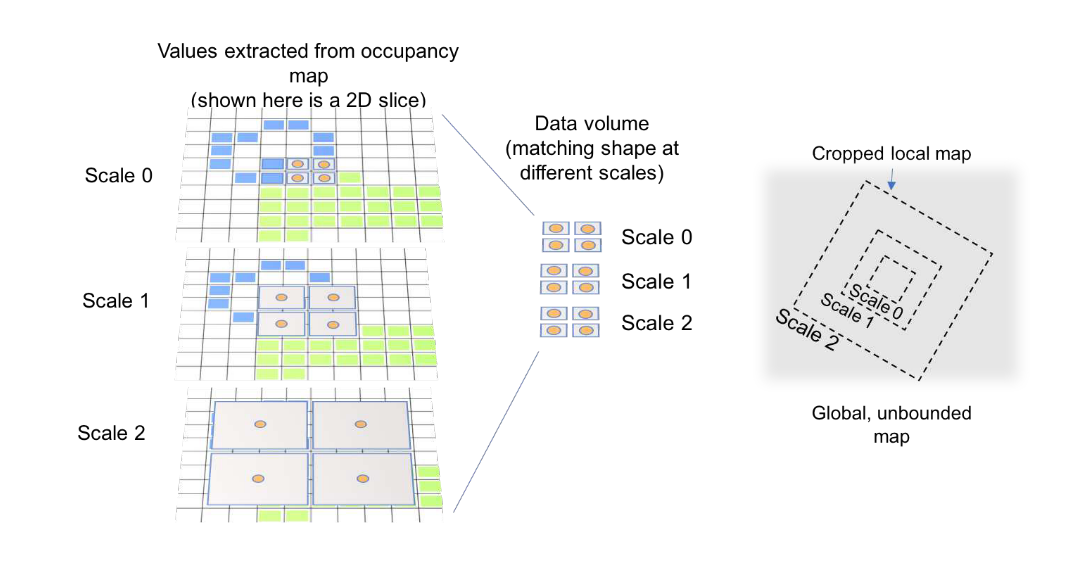 首先截取$D_x\times D_y \times D_z$的栅格。根据八叉树地图的性质,可以很容易的这些栅格按照$2^l \times r, l\in(1, …,L) $的分辨率降采样。然后将这些三维栅格旋转与平移到p的位置,并且依靠三次插值来将三维栅格压缩成二维栅格。因此一个多尺度的representation为$x(M, p)\in \mathbb{R}^{D_x\times D_y \times D_z \times 2L}$。其中2是表示每个尺度都有一个occupancy与一个uncertainty图。
首先截取$D_x\times D_y \times D_z$的栅格。根据八叉树地图的性质,可以很容易的这些栅格按照$2^l \times r, l\in(1, …,L) $的分辨率降采样。然后将这些三维栅格旋转与平移到p的位置,并且依靠三次插值来将三维栅格压缩成二维栅格。因此一个多尺度的representation为$x(M, p)\in \mathbb{R}^{D_x\times D_y \times D_z \times 2L}$。其中2是表示每个尺度都有一个occupancy与一个uncertainty图。
ConvNet Architecture

总结
利用深度学习,学习nbv的评估函数。
12-14
- 标题:Learned Map Prediction for Enhanced Mobile Robot Exploration
- 作者单位:Simon Fraser University
- 会议: ICRA 2019
System Overview
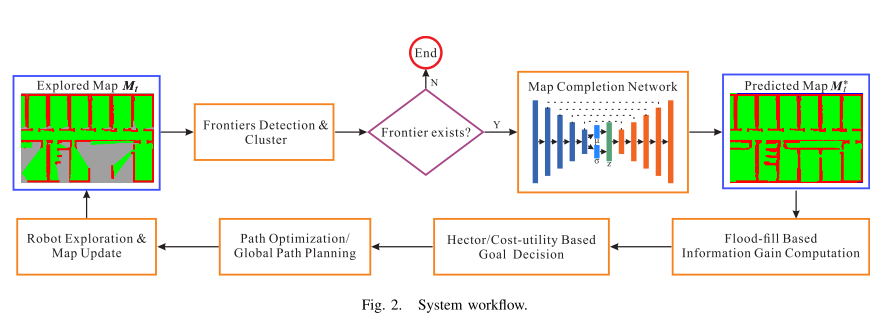
Map Completion Network
使用变分自编码器(VAE)。
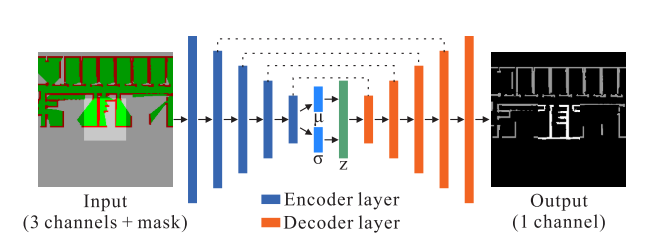
Encoder使用的是resnet结构。输出一个均值$\mu$与log 方差$log(\sigma)$,尺寸均为$8\times 8\times 512$。
Decoder与Encoder采用的是类似的结构,但是用转置卷积。输出是一个障碍物的概率图。用阈值0.5来决定是障碍物还是free space.
损失函数为
- 预测损失。二值交叉熵损失。 \(l_{n}=-\left[y_{n} \cdot \log x_{n}+\left(1-y_{n}\right) \cdot \log \left(1-x_{n}\right)\right]\) 其中$y_n$是groundtruth label, $x_n$是输出label。 则总体损失为: \(L_{\text {prediction}}=\sum l_{n}\)
- KL 散度损失。 \(L_{k l d}=\sigma^{2}+\mu^{2}-\log (\sigma)-1\) 该损失使得训练得到的分布接近于正态分布。
- 总体损失 \(L_{\text {final}}=\gamma L_{\text {prediction}}+(1-\gamma) L_{\text {kld}}\) 其中$\gamma$在本文中取0.99。
Map Completion Augmented Exploration
Information Gain Computation
首先通过dfs找到所有的边缘点聚类。则每个边缘点聚类的信息增益可以定义为 \(\boldsymbol{I}_{t}^{i}\left(\boldsymbol{M}, x_{i}\right)=\boldsymbol{H}(\boldsymbol{M})-\boldsymbol{H}\left(\boldsymbol{M} \mid x_{i}\right)\) (这个很常见就不解释了)。 对于一个占据栅格地图,香农信息熵定义为: \(\boldsymbol{H}(\boldsymbol{M})=-\sum p\left(m_{j}\right) \log p\left(m_{j}\right)+\left(1-p\left(m_{j}\right)\right) \log \left(1-p\left(m_{j}\right)\right)\) (这个也很常见,也不解释了)
Augmenting Exploration Planners
基于Hector exploration与cost-utility function based planner。
- Augmented Hector Planner: 传统的Hector Planner有两个损失,路径到frontier的距离损失与障碍物的损失。增强 的Hector Planner的损失可以表示为: \(\boldsymbol{C}(m)=\min _{\mathbf{F}_{i}^{i} \subseteq \mathcal{F}_{t}}\left\{\min _{f \in \mathbf{F}_{i}^{i}} \boldsymbol{C}_{p}(f)-\alpha \sqrt{\boldsymbol{I}_{t}^{i}}\right\}+\beta \boldsymbol{C}_{o}\)
其中$C_p(f)$为当前栅格m到frontier栅格f的距离。$I_t^i$是frontier 聚类$F_t^i$的信息增益,$C_o$为当前cell m的碰撞损失。$\alpha \beta $是两个认为给定的参数。
- Augmented Cost-Utility Planner: \(\boldsymbol{C}(f)=\boldsymbol{C}_{p}(f)-\lambda \sqrt{\boldsymbol{I}(f)}\) 其中$C_p(f)$为当前栅格m到frontier栅格f的距离。$I_t^i$是frontier 聚类$F_t^i$的信息增益。
12-15
- 标题:Fast Frontier-based Information-driven Autonomous Exploration with an MAV
- 作者单位:ETHZ && 伦敦帝国学院(Imperial College London)
- 会议: ICRA 2020
Frontier-based Information-driven Exploration Algorithm
在每一次planning iteration中执行以下步骤:
- 从frontier voxels中生成预先指定数量的candidate goal.
- 规划当前位置到候选位置的无碰触的路径
- 给每个candidate postion关联一个yaw角从而创造出一个candidate pose,再用utility function来评估信息增益
- utility score最高的位置被选为下一次的目标。
MAV Model
无人机状态量为$\mathtt{x} =[x, y, z,\psi]$,其中$\psi$为yaw角。并假设无人机有一个安全的碰撞半径$R\in \mathbb{R}^+$。
Map representation
本文使用了 Supereight: 一个框架,集成了octomap 以及使用octomap的快速SLAM方案。 该框架的论文为:Efficient Octree-Based Volumetric SLAM Supporting Signed-Distance and Occupancy Mapping
莫顿码(Morton Code):一种编码方式,将多维坐标编码成一维数据。
在八叉树的叶子节点处,supereight没有存储单个voxel,而是存储了$8\times 8 \times 8$的voxel块。
该文章对其进行了改进,使得其
- 能够存储一个栅格是否是边缘的信息
- 占据概率能够向上传播,使得碰撞检测容易实行。
Frontier Detection
每当新的measurement被加入到地图中时,仅对被更新的voxel检测是否是frontier.
frontier voxel的定义:其占据概率小于0.5,且六邻域的voxel的占据概率等于0.5(即未知)。即那些紧邻着未知区域的free voxel。
Candidate Position Sampling
每个frontier voxel块里的frontier个数被求出来,并且小于某个数量的frontier 块会被忽略。剩下的块组成集合$F$
由于$F$中的块使用莫顿码来构建空间上的索引,因此对莫顿码进行均匀采样即可得到空间上均匀采样的frontier voxel blocks。对于每个block,随机选取其中的一个frontier voxel的坐标作为候选位置$P_i$,并且当前位置的yaw角也作为候选位置的yaw角(因为不需要多余的旋转)。
Path Planning to Candidate Positions
路径规划是用的OMPL里的Informed RRT*。因为边界区域附近有未知区域,因此导航的时候仅导航到候选区域的前面一部分,然后再直线走到未知区域去。
还提到在模型预测控制(receding horizon exploration)里,由于飞行器是边走边预测的,因此会导致在某些狭小的区域会往复运动。
Yaw Optimisation and Candidate Pose Evaluation
Sparse Raycasting and Yaw Optimisation:
稀疏光线投射的原理我可以看一下,文章为: Safe local exploration for replanning in cluttered unknown environments for microaerial vehicles
所谓的yaw角优化,其实是构造360度的光线投射的信息增益图:
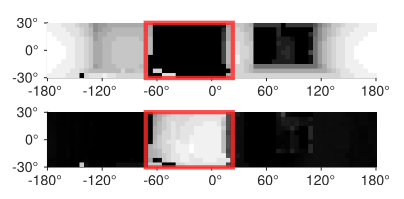
这个图的上面一张为深度图,下面一张为信息增益图。通过滑动窗口的方式选择出最佳的信息增益。
Utility Function
\(u\left(\mathbf{x}_{i}, \hat{W}_{i}\right)=\frac{\mathbb{H}\left(\mathbf{x}_{i}\right)}{T\left(\hat{W}_{i}\right)}\)
分子为候选位置的信息熵,分母为规划出来的路径,飞行器所需要的飞行时间。
12-16
- 标题:Safe Local Exploration for Replanning in Cluttered Unknown Environments for Microaerial Vehicles
- 作者单位:ETHZ-ASL
- 期刊:RAL 2018
这一篇是上述提到的稀疏光线投射。
Local Trajectory Optimization
先介绍几个概念
- Jerk: 加速度的倒数 \(\vec{\jmath}(t)=\frac{\mathrm{d} \vec{a}(t)}{\mathrm{d} t}=\frac{\mathrm{d}^{2} \vec{v}(t)}{\mathrm{d} t^{2}}=\frac{\mathrm{d}^{3} \vec{r}(t)}{\mathrm{d} t^{3}}\)
- Snap: Jerk的倒数 \(\vec{s}=\frac{d \vec{\jmath}}{d t}=\frac{d^{2} \vec{a}}{d t^{2}}=\frac{d^{3} \vec{v}}{d t^{3}}=\frac{d^{4} \vec{r}}{d t^{4}}\)
然后认为局部待规划的轨迹在K维空间中,有S段segment构成,每段segment是时间的N阶倒数,表达式为 \(f_{k}(t)=a_{0}+a_{1} t+a_{2} t^{2}+a_{3} t^{3} \ldots a_{N} t^{N}\) 设这个多项式的系数为 \(\mathbf{p}_{k}=\left[\begin{array}{lll} a_{0} & a_{1} & a_{2} & \ldots & a_{N} \end{array}\right]^{\top}\)
…… 这部分有机会再看,我知道他就是最小化snap以及障碍物的损失以及一个soft cost
Map Representation and Unknown Space
Voxblox: 从octomap建立的阶段距离符号场(TSDF)
设置未知的Voxel为占据状态。为了之后的导航规划使用。
Intermediate Goal Selection
对比使用了几个不同的全局规划器:
- naive random waypoint selection: 随机选点
- optimistic RRT* (unknown = free)
- pessimistic RRT* (unknown = occupied)
- RRT+nbv
- Proposed
这里介绍下Proposed的方法吧。
- 在free的区域随机选取N个点,这N个点的yaw角由飞机飞到这个位置的真实yaw角决定。
- 所谓稀疏的光线投射是指,在传感器模型的投射区域,计数位置的voxel的数量。为了实时运行,可以对frustum进行降采样,并且只检测每个降采样后的栅格的第s个voxel。
12-22
- 标题:Virtual Maps for Autonomous Exploration with Pose SLAM
- 作者单位:斯蒂文斯理工大学(二作为Lego-LOAM和Lio-SAM的作者Tixiao Shan)
- 期刊:RAL 2018
经过将近一个星期的阅读,我只能说,噫,好,我读懂了。
待选路径的生成
将当前位置到所有地图边界的直线连接作为初始值,并将这些初始值按照以下方法优化:
首先,该论文构造了了两个costmap: Localization cost map 和 Exploration cost map.

设$d(x_i, x_j)$为两个位置之间的pose,$d_{\text{occupied}(x)}$与$d_{\text{observed}(x)}$为当前的pose到最近的占据的栅格的距离和到最近的观察过的栅格的距离,并且定义$r_{\text{sensor}}$为传感器的最长的测距距离,则可以定义定位损失为
\(\lambda_l(x_j) = 1-\exp \left(-a_{l} d_{\text {occupied }} / r_{\text {sensor }}\right)\) 定义探索损失为 \(\lambda_{e}\left(\mathbf{x}_{j}\right)=\exp \left(-a_{e} d_{\text {observed }} / r_{\text {sensor }}\right)\) 这就是上述两幅图的来源。
在当前时刻T,希望找到由N个pose组成的路径,使得下面的损失函数最小 \(\sum_{i=1}^{N}\left(w_{0}+w_{l} \lambda_{l}\left(\mathbf{x}_{T+i}\right)+w_{e} \lambda_{e}\left(\mathbf{x}_{T+i}\right)\right) d\left(\mathbf{x}_{T+i-1}, \mathbf{x}_{T+i}\right)\)
关于$\omega_0, \omega_l, \omega_e$的选择,采用的是帕累托优化方法(Pareto optimal solutions):
帕累托最优是指资源分配的一种理想状态。給定固有的一群人和可分配的资源,如果从一种分配状态到另一种状态的变化中,在没有使任何人境况变坏的前提下,使得至少一个人变得更好,这就是帕累托改善。帕累托最優的狀態就是不可能再有更多的帕雷托改善的狀態;换句话说,不可能在不使任何其他人受損的情況下再改善某些人的境況。
这里通过调整\(w_{l} \in[0,1]\)且$w_{e} = 1 - w_l$来实现。
期望最大化探索(EM Exploration)
SLAM问题可以用以下联合概率问题来表示 \(X^{*}, L^{*}=\underset{X, L}{\operatorname{argmax}} \log P(X, L, Z)\) 其中$X$为机器人的位置,$L$为landmarks,$Z$为观测。 在传统的联合概率之上,该文章引入了虚拟landmarks V,指在探索过程中会出现的可能没被观测过的landmarks。则目标函数可以被改为:
\[\begin{aligned} X^{*} &=\underset{X}{\operatorname{argmax}} \log P(X, Z) \\ &=\underset{X}{\operatorname{argmax}} \log \sum_{V} P(X, Z, V) \end{aligned}\]在本文中,用了两步法来求解这个问题: \(\begin{array}{l} \text { C-step: } \quad V^{*}=\underset{V}{\operatorname{argmax}} p\left(V \mid X^{\text {old }}, Z\right) \\ \text { M-step: } \quad X^{\text {new }}=\arg \max _{X} \log P\left(X, V^{*}, Z\right) \end{array}\) 这个就是所谓的classification EM algorithms。(这种EM算法的思想我没看,但是这个公式倒是挺好懂。)现在假设$Z$是使得$X, V$似然概率最高的观测,那么,求得$X,V$后,$Z$就唯一确定,$Z$的概率不影响$X,V$的概率,则有
\[P(X, V, Z)=\mathcal{N}\left(\left[\begin{array}{l} X \\ V \end{array}\right],\left[\begin{array}{ll} \Sigma_{X X} & \Sigma_{X V} \\ \Sigma_{V X} & \Sigma_{V V} \end{array}\right]\right)\]这个公式的解可以转化为以下问题:
\[\underset{X}{\operatorname{argmax}} \log P\left(X, V^{*}, Z\right)=\underset{X}{\operatorname{argmin}} \log \operatorname{det}(\Sigma)\]为什么?因为上述高斯分布的均值总是$X,V$,即你取任何$X, V$,这个概率分布的值总是一个高斯分布的最大值。而高斯分布的最大值取决于其协方差,协方差的行列式越小,其最大值越大。
对于一个正定的协方差矩阵,其行列式有以下关系: \(\underset{X}{\operatorname{argmax}} \log P\left(X, V^{*}, Z\right)=\underset{X}{\operatorname{argmin}} \log \operatorname{det}(\Sigma)\) 即一个正定矩阵的行列式应该小于其对角线的两个矩阵的行列式之和。
接下来就是确定这个协方差的上界。
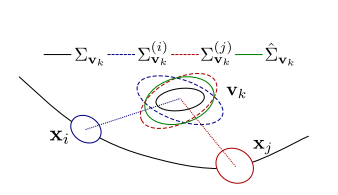
这部分由于时间关系我不详述了。
工具函数
在根据上述方法找到一系列的candidate path后,还要选出一个最好的路径。这里使用了一个utility函数为 \(\begin{aligned} U_{\mathrm{EM}}\left(X_{T: T+N}\right)=&-\log \operatorname{det}\left(\tilde{\Sigma}_{\mathbf{x}_{T+N}}\right)-\sum_{k} \log \operatorname{det}\left(\hat{\Sigma}_{\mathbf{v}_{k}}\right) \\ &-\alpha d\left(X_{T: T+N}\right) \end{aligned}\)
即我选择的路径不光本身路程要短,并且还要让landmarks的协方差的行列式降到最低。
12-28
- 标题:Robust Exploration with Multiple Hypothesis Data Association
- 作者单位:斯蒂文斯理工大学
- 期刊:IROS 2018
一些概念:
- 分枝定界(Branch and Bound):对有约束条件的最优化问题(其可行解为有限数)的可行解空间恰当地进行系统搜索,这就是分枝与定界的内容。通常,把全部可行解空间反复地分割为越来越小的子集,称为分枝;并且对每个子集内的解集计算一个目标下界,这称为定界。在每次分枝后,凡是界限不优于已知可行解集目标值的那些子集不再进一步分枝,这样,许多子集可不予考虑,这称为剪枝。这就是分枝定界法的主要思路。
主要内容
利用多假设树来做数据关联的。和我的课题相关性暂时不是很大(我的机器人还没考虑定位问题)。先不花时间考虑了。
12-31
- 标题:Uncertainty-Aware Occupancy Map Prediction Using Generative Networks for Robot Navigation
- 作者单位:约翰霍普金斯大学
- ICRA 2019
(还是深度学习的文章好懂)
这篇文章就是依赖于U-Net结构对二维栅格地图进行补全。
创新点:
- 不是一张图输入后,只输出一张补全的图,而是输出多张补全的图。损失函数用多张输出的图的加权平均与真值做比较,这样的好处是多张输出的图会比单张输出的图更加的锐利,模糊的地方更少(下图中的b为单张输出,c d为多张输出。

- 在生成多个图后,求这些图在每个像素上方差,获得一个方差图,如图(e)所示。
- 对图(e)进行栅格的划分,然后选择方差和最大的那个栅格的中心点,作为下次探索的位置。
1-5
- 标题:Graph-based Path Planning for Autonomous Robotic Exploration in Subterranean Environments
- 作者单位:内华达大学
- IROS 2019
粗略看了下,利用了Local planner 选择当前信息增益最大的路径, 利用Global planner 使得机器人在探索洞穴时还能够返回。
1-7
- 标题:Receding horizon path planning for 3D exploration and surface inspection
- 作者单位: ETHZ
- Autonomous Robots 2016
这篇其实我之前读过,但是当时印象不是很深刻。现在重新回顾一下。
一些概念
- receding horizon = mpc(模型预测控制)
- residual volume: 从configuration空间中找不到一个configuration可以将其照到的voxel的集合.
信息增益表达式
\(\operatorname{Gain}\left(n_{k}\right)=\operatorname{Gain}\left(n_{k-1}\right)+\mu\left(\text { Visiblev }\left(\mathcal{M}, \xi_{k}\right)\right) e^{-\lambda c\left(\sigma_{k-1}^{k}\right)}\)
其中$\text { Visiblev }\left(\mathcal{M}, \xi_{k}\right)$表示给定地图M以及机器人位置$\xi$,其可视区域内有多少尚未被看到的voxel。$e^{-\lambda c\left(\sigma_{k-1}^{k}\right)}$是路径损失。
算法流程
- RRT*算法在free space生成候选位置。
- 用上述的信息增益表达式,选出信息增益最大的节点。
- 选出最大的节点(以及其对应的路径后),只执行第一步,当第一步执行完后,保留当前最佳路径,其他节点丢弃,然后重复123步来继续执行下一步。这就类似于MPC的味道在里面了。
1-11
- 标题:Reactive Control and Metric-Topological Planning for Exploration
- 作者单位: 科罗拉多大学博尔德分校
- ICRA 2020
一篇结合了现代控制理论和边界探索的文章。这篇文章讲的是机器人在隧道型场景下的主动探索。Paper Reading可以讲一下这一篇。挺有新意。
Nearness-Based Control
在隧道中肯定希望机器人沿着隧道路径的中心移动以避免碰撞。这篇文章将机器人到360度的距离进行了建模,并且设计了一个反馈器来镇定系统,使得机器人的位置始终在隧道路径的中心。

Planning
通过一些SLAM方法获得二维占据栅格地图后,对地图进行二值化,并且使用高斯滤波平滑,再通过腐蚀操作细化路径,得到下图所示。

然后统计地图中节点度为1的node,这些node要么就是死胡同,要么就是待探索的区域,通过近邻搜索来将这些node连接起来,然后让机器人走到最近的待探索的度为1的node,即完成了自动探索。
1-15
- 标题:Efficient Autonomous Exploration Planning of Large-Scale 3-D Environments
- 作者单位: KTH & 林雪平大学
- RAL 2019
信息增益表达式
\[s(\mathbf{x})=g(\mathbf{x}) \exp (-\lambda c(\mathbf{x}))\]$g(x)$为x处的信息增益,$c(x)$为当前位置到x位置的损失,$lambda$是一个人为的参数。
方法论
利用高斯过程来计算一个新的candidate的信息增益,并且用协方差来判断得到的信息增益是否准确,如果不够准确则再采用光线投射的方法获得信息增益。
结合frontier exploration + nbv的方法来实行主动探索。
实现
Sparse Ray Casting
不还是数格子吗。
Collision Checking
看以起点与终点为两端的圆柱体里是否有占据的voxel。
Gaussian Process Interpolation
- 零均值假设
- RBF-kernel \(k\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\exp \left(-\frac{1}{2}\left\|\mathbf{x}_{i}-\mathbf{x}_{j}\right\|^{2}\right)\)
1-15
- 标题:Guiding Autonomous Exploration With Signal Temporal Logic
- 作者单位: KTH
- RAL 2019
和上一篇文章有相同的作者。主要的贡献是,将人为指定的约束加入到轨迹规划中,使得路径更加好看。
具体公式为: \(c\left(\sigma_{k}^{k+1}, \psi\right)=C\left(\sigma_{k}^{k+1}\right) \max \left(e^{-\beta \rho\left(\psi, \sigma_{k}^{k+1}\right)}, 1\right)\)
这个我可以用到最后的nbv评估当中去。