背景
PointNet 是Point cloud的Object detection问题的近乎奠基的论文。作者来自于Stanford,PointNet发表在CVPR 2017。这篇文章是VoxelNet(CVPR2018)的指导思想,VoxelNet将PointNet的功能由分类拓展到定位+分类。
难点
点云point cloud的object detection相比较于图片, 有以下三个性质或者难点:
- 无序性。图片中的像素依次排列,而点云中的点没有特定的顺序。这就要求神经网络对拥有N个点的点云,任意交换其中任意点的输入顺序,网络能够有相同的输出。
- 点之间的相关性。点不是孤立的,特定范围内点集是有意义的,表示特定范围内的特征,要求网络能够提取这种特征。
- 旋转不变性。对于表征同一个物体的点云,将其进行刚体变换后,作为网络的输入,网络应该能够得到相同的输出。
网络结构
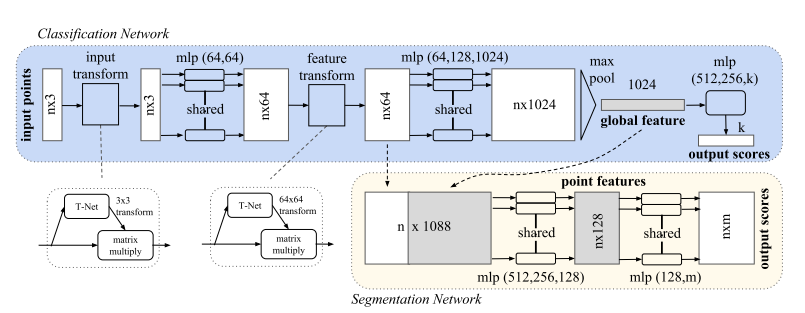
蓝色框中为做Classification任务的网络。红色为做Segmentation任务时的网络。 做Classification任务时,每个输入的点云仅代表一种物体。
为求简洁,只看蓝色部分以及两个T-Net。
MLP与Max pooling
- MLP:Multilayer perceptron(多层感知机)。我的理解就是全连接层。
- Max pooling: 最大值池化。池化即为一种降采样,最大值池化就是在指定窗口中选择最大值作为对这个窗口降采样后的值。
PointNet网络大意
上图的input transform和feature transform先不看,那么PointNet就很简单了:
- 一帧点云nx3个数据, 经过全连接层(64x64)后变为nx64,再经过一个全连接层(64,128,1024)后变为nx1024。
- Max pool对nx1024进行池化降维,变为1x1024。这1024个特征即为该点云的特征向量,并且不论点云原来的n是多少,特征向量都为1x1024。
- 最后经过一个512x256xk的全连接层(k为分类问题的类数),得到Scores。
T-net
如果没有input transform和feature transform,上述的网络并没有解决旋转不变性。
PointNet认为,要解决旋转不变性,就要对点云做处理。一种思路是将所有点云都提前旋转到一个标准的空间位置(a canonical space)。比如一幅点云表示椅子,则先将椅子旋转到与地面平行再把这个点云喂给网络。有Paper做了这个工作,但是PointNet采用了另外一种思路:
PointNet想法和上面差不多,但是它没有人为地去计算要把椅子旋转到与地面平行的旋转矩阵,而是让T-net去学习这个旋转矩阵!
T-net图中没有画出其结构,不过论文中有写,其结构为:
- 输入为nx3点云
- 一个64x128x1024的全连接层。
- 对该全连接层进行池化,得到1x1024个特征。
- 再经过一个512x256x9的全连接层,得到一个1x9的向量。
- 将该向量变为3x3的矩阵,则该矩阵则为旋转矩阵。
- 用该旋转矩阵对原始点云进行处理。
可以看出,T-net与PointNet结构非常相似。
可能是觉得这样做效果不太好,后面又加了个feature transform去旋转特征。
理论证明
PointNet里论证了为什么他们这个网络函数对任意点云能够解决其无序性的问题。用到了集合的理论。公式太复杂,我的理解就是关键在于这个Max pooling。它将之前与点云顺序有关的nx1024个神经元降采样到1x1024个特征,这样就与原始点云顺序无关了。原始证明我并不太看得懂,在附加链接中。