挖的坑要及时填呀。
背景
户外大尺度环境下做SLAM一般是用激光雷达传感器与相机。如果直接保存点云地图,则由于户外机器人运动的范围比较大,地图的占用内存会过大。因此ETHZ-ASL实验室提出了一种基于segment的地图,能够将点云地图很好的抽象,适合于多机器人户外大范围环境的探索与建图。
相关论文
一篇是发表在ICRA 2017的SegMatch1,另一篇是基于此18年发表在RSS上的SegMap2,这篇文章主要介绍SegMatch,下一篇文章则会介绍SegMap。
SegMatch
SegMatch 解决的是激光雷达SLAM问题中的位置识别(place recognition)问题。位置识别问题常出现在回环检测中,主要是确认这个场景是否来过。
对于视觉SLAM,一般来说位置识别就用提取特征点与词袋模型来做了。不过视觉SLAM会有视角(View point)的问题。举例来说,小车从A开到B,与从B开到A,视觉看到的景象是不同的,自然也就形成不了回环。
然而激光SLAM就没有这个问题。激光雷达360扫描,视场角很好的覆盖了所有的区域。在这篇文章中,作者认为激光的位置识别主要有两种提特征的方式: local feature 与global feature。
local feature主要还是提取特征点与匹配。这样提的特征做位置识别,由于特征是局部的,因此匹配的成功率会比较低。
global feature是指对于输入的整个点云,分析点云的一些特征并抽象出来,比如得到一个关于点云的直方图,再拿直方图去匹配。这样做的缺点是,机器人的位置稍作变化,输入点云的global feature就可能不一样。即global feature的一致性比较差。
因此作者从中取舍,对点云进行分割,得到许多关于三维物体的点云,再用这些点云去完成place recognition问题。
SegMatch的流程图如下所示。
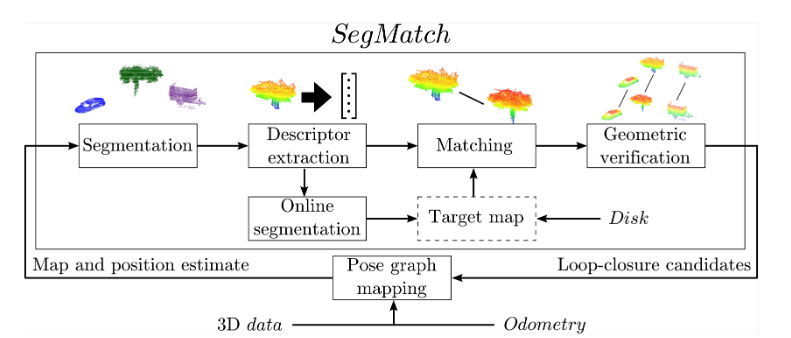
我将详细介绍每个部分的作用。
Segmentation
- 首先只选取机器人所在一个特定范围内的点云。
- 然后用Voxel grid 滤除一些噪声点。这里我认为是数每个体素内的点的数量,小于一定阈值的则丢弃。
- 最后就是用点云进行分割了。这里用了3中提到的”cluster-all”方法。主要算法为: a. 首先去除地面。如果相邻两个体素的点云的协方差信息与垂直方向上的平均值相差不大,则可以将这两个体素划为一类。最后根据这个方法得到的最大的聚类即为地面。 b. 然后使用欧氏距离聚类的方法对剩下的点云进行聚类。欧氏距离聚类的方法有点类似于二维的广度优先搜索。
Feature extraction
首先,每个聚类称之为cluster。对于上面Segmentation得到的clusters,利用许多人工特征来生成这些cluster的signature。signature直译为签名,在这里可以理解为每个cluster的“唯一身份证”。比较两个Cluster是否相似,只需比较他们的signature是否相近即可。
这里作者使用了两种signature:
- $f^1$ Eigenvalue based: 在这种描述子中,signature是一个1x7的向量,包括点云的线性(linearity), 平面性(planarity), 散射性(scattering), 各向同性(omnivariance), 各向异性(anisotropy), 特征熵(eigenentropy)和曲率( change of curvature)。这些特性的计算方法定义在4中。
- $f^2$ Ensemble of shape histograms: 是一个1x640的向量,由十个64字节的直方图组成。这十个直方图包含了D2,D3,与A3的信息。
- D2: 是任意两个点的距离的直方图。
- D3: 是任意三个点组成的三角形的面积的直方图。三维点有三个维度,故有三个D3直方图。
- A3: 随机采样三个点,形成两条直线,这两条直线构成的角的度数的直方图。
- ratio: 任意两个点连接的直线中,直线在物体表面上与直线在空中的比例关系。 具体描述可以详见文章5。有3个D2直方图+3个D3直方图+3个A3直方图+1个Ratio,共十个直方图。
Segment matching
使用随机森林作为分类器,判定两个Cluster是否是同一个物体。
有关随机森林的介绍可以参见周志华的《机器学习》的集成学习那一章。我的理解是多个决策树的组合。
对于$f^1$的描述子,将两个Cluster的特征向量的差的绝对值以及这两个Cluster本身,一共是1x21维的向量喂给随机森林分类器。
对于$f^2$的描述子,计算每个直方图的交集,得到1x10的向量,并喂给随机森林。
最后对随机森林的输出人为设定阈值即可。
Geometric verification
这部分还有待理解,主要的思想应该是用RANSAC方法,根据当前点云cluster的中心点与地图中的cluster的中心点算机器人到地图的transform。
实验部分
以前看论文一直是轻实验重方法论,其实实验部分也是有很多很有意思的东西的。
数据集
- 使用Kitti的06序列来训练随机森林,00序列来测试回环,05序列来测试整个框架的实时性(存疑)。
- 去除地面的操作是直接通过设置一个最大高度阈值来去除的。
- 以机器人(车)为圆心,画60m的半径,再用半径为0.1m的体素来划分点云。每个体素内至少需要有两个点。
- 欧氏距离聚类的阈值为0.2m。选取点在100~15000内的segment。
训练与测试
首先对一个序列,生成一个全是segment的地图。接着当车辆经过某个区域时,对局部地图中的每个segment,找距离与其最近的K个segments(KNN),分别存储为true corresponding match 与false corresponding match。随后按照比例采样扔给决策树去雪莲。
匹配方法比较
三种方法:
- L2范数法。直接计算两个signature的欧式距离。
- 使用前文提到的$f^1$
- 使用前文提到的$f^1 + f^2$
其ROC曲线为:
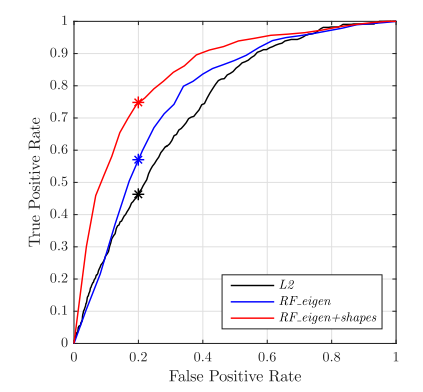 可以看出第三种方法是效果做好的。
可以看出第三种方法是效果做好的。
定位表现评判
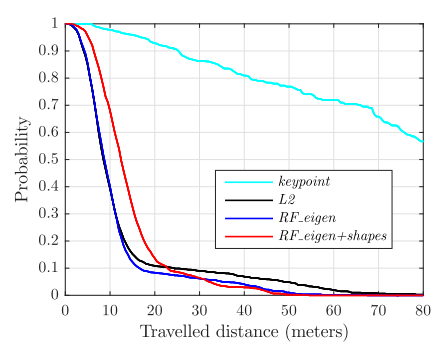
这三种方法的定位表现的比较。纵轴是能够定位的概率,横轴是车辆的行进距离。可以看到行进大约50m后基本都能够定位。