填坑。
背景
在上一篇文章中,对于点云聚类的分类是利用传统机器学习算法——随机森林去做的。而喂给随机森林的不是 点云聚类自身,而是其人工提取的特征向量(或者特征直方图)。这样的做法,分类的效果受限于人工特征 自身的鲁棒性。因此本文提出了数据驱动的CNN分类器来提取特征描述子。
SegMap
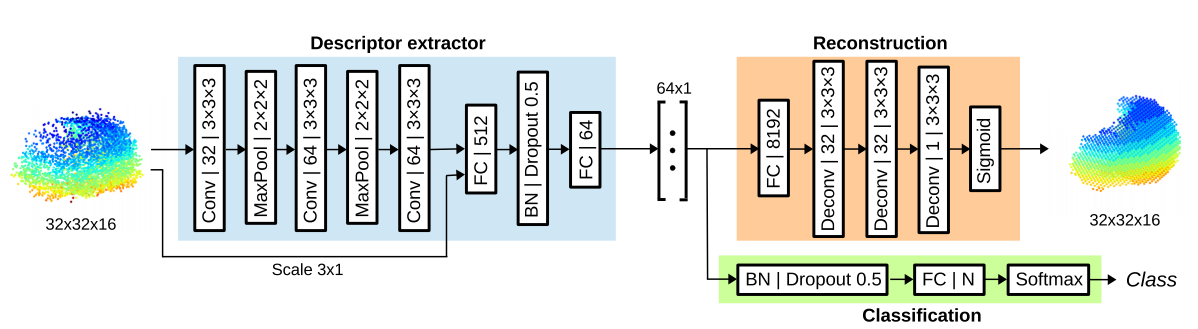
一张图涵盖segmap的所有内容。
最左侧是网络的输入。首先将空间分为32*32*16个体素,每个体素的值为0或者1, 表示这个体素内有无三维点。随后喂给卷积网络。
特征提取部分
稍微要注意的是,这里用的是三维卷积与池化。激活函数用的是RELU。
Segment Alignment adn scaling
为了保证属于同一类物体的每个Segment作为体素输入时比较相近,这儿有一个Segment对齐的操作。首 先,对每个segment进行PCA, 然后将这个segment旋转,使得其x轴与其最大的特征向量的方向一致(显然这样的旋转有二义性)。为了消除上一步的二义性,同样该旋转会使得y轴的负半轴区域会拥有最多的三维点的数量。
每个体素的最小尺寸为0.1m, 而最大尺度没有受限制,从而使得所有体素可以将这个物体包围住。
训练
这里提出了一个特殊的训练技巧。
网络中有两个部分,一个部分是特征提取,另一个部分是根据特征描述子重建这个segment。设特征提取的损失为$L_c$, 重建的损失为$L_r$, 那么这个网络的总损失为 \(L = L_c + \alpha L_r\)
$\alpha$ 是一个权重系数,用来平衡重建与特征提取的效果。文中说$\alpha = 200$ 效果是比较好的。权重初始化用的是Xavier的初始化方法, 训练用的是ADAM优化器。以下解释两个Lost的构建。
分类误差$L_c$
softmax交叉信息熵损失: \(L_{c}=-\sum_{i=1}^{N} y_{i} \log \frac{e^{l_{i}}}{\sum_{k=1}^{N} e^{l_{k}}}\)
$y_i$ 为One hot encoded vector(深度学习术语, 待补充)
重建误差$L_r$
\(L_{r}=-\sum_{x, y, z} \gamma t_{x y z} \log \left(o_{x y z}\right)+(1-\gamma)\left(1-t_{x y z}\right) \log \left(1-o_{x y z}\right)\) (待补充)