背景
做毕业设计的时候,发现在大场景(80m*60m,八叉树栅格分辨率为0.4m)下,将点云塞入到八叉树栅格时,计算量太大而导致无法实时。于是想到用CUDA来加速光线投射。
HelloCuda
__global__ void cuda_hello(){
printf("Hello World from GPU!\n");
}
int main() {
cuda_hello<<<1,1>>>();
return 0;
}
以上是一个最简单的cuda程序:
- __global__ 修饰符表示这个函数是一个运行在gpu上的函数。
- main函数里执行cuda_hello«<1, 1»>,表示调用一个线程块(thread blocks),每个线程池有1个线程。则这个函数会被执行1*1次。 实际情形中,每个线程块内的线程数量是有规定的。以RTX 2070为例, 每个线程块可以同时有1024个线程。而线程块的数量则是可以任意的。(补充一句,这里的线程块,其实是对应了显卡上的sm(stream multipleprocessors 流处理器),虽然显卡上的流处理器数量是一定的,但是超出流处理器的数量的线程块会排队等待空闲的流处理器去执行他)、
上述程序需要使用nvcc来编译。nvcc是nvida c compile的缩写,专门用来编译cuda程序。
八叉树里的光线投射
在构建三维栅格地图(八叉树地图)的过程中,一个不可避免的操作就是使用光线投射来得到free 栅格与occupied栅格。
以下图为例,假设机器人的坐标为$(x_1, y_1)$,在点$(x_2, y_2)$处有一个观测(比如说激光雷达的点云的某一个点),那么可以认为$(x_2, y_2)$处的点是occupied的,而这两个点的连线所经过的栅格是free的。计算从起点到终点所穿过的栅格,在八叉树里就被叫做castRay。
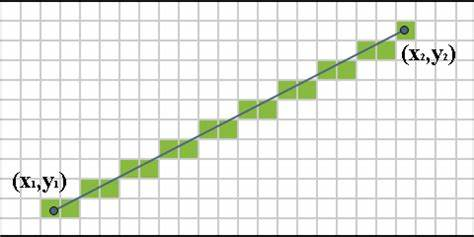
可以看出castRay其实是一个高度可并行的过程,因为只要地图不变,那么给定不同的起点与终点做castRay,彼此是毫无干涉的。(这里的干涉是指两个task并行的过程中,一个task会阻塞另一个task)。
如何进行光线投射的加速
有了前面的理论基础后就可以进行尝试设计代码了。这里还遇到一个问题:
octomap类的所有成员变量都是放在cpu上的,并且所有成员函数都没有声明可以被gpu调用(导致你在gpu的核函数里不能调用octomap的光线投射算法)。
前者好解决,只要在cuda上新建一个类就好,后者其实很难解决,有国外网友的做法是给所有的要用到的octomap的函数加上__device__修饰符,但这意味着要修改octomap库的源码,不是一个好的方法。
我的解决方法是既然octomap不能被声明到gpu上,那我重新搞一个gpu上的数据结构,使得octomap里面的Node都可以被存储到这个数据结构上,然后计算光线投射的时候,直接从这个数据结构里面访问数据就好了。
但是如何选择合适的数据结构?我之前看过Voxel Hashing的论文,觉得哈希表是一个比较好的数据结构,因此我就直接拿来用了。GPU上创建hash表的代码有一些,我这里选择了一个不需要使用任何库的热心网友的实现.
此外,光线投射的函数也需要从octomap里面抄过来并且做了一定的修改,原先是从octomap类自身的数据里查找node,修改为从hash表里查找node。
所以,总结一下,用cuda加速光线投射的办法为:
- 在cuda上创先一个哈希表,并且将octomap里的node插入到hash表中,哈希表的key为node的key,哈希表的value为node是否占据的信息(0为unknown, 1 free, 2 occupied)
- 将需要并行进行的光线投射的所有起点与终点,组合成两个数组,并且将数组从CPU搬到GPU上。
- 调用kernel函数并行执行光线投射,我这里的kernel函数的参数为:
__global__ void
kernelCastRay(KeyValue *hash_table, double resolution,
const unsigned int cast_num, octomap::CudaPoint3d *origins,
octomap::CudaPoint3d *dirs, octomap::CudaPoint3d *end_pts,
bool ignore_unknown, double *max_ranges, bool *find_end_pt) {
unsigned int thread_id = blockIdx.x * blockDim.x + threadIdx.x;
···
/* octomap里面的光线投射算法 */
}
整个部分的源码我已经放到了EpsAvlc_toys里面去了,有兴趣的人可以去看一看。
总结
实际上这个还是一个比较简单的cuda编程的应用,还有很多复杂的内容,比如线程之间的共享内存什么的,都没有涉及,囿于本人自身的专业性以及毕业设计的需求,我就不继续研究了。
我觉得要用cuda来加速你的程序,主要有两点考量:
- 需要加速的部分,是不是可以并行的,或者说可以并行的部分有多少。
- 如果需要加速的部分并非你自己的代码,如何将其转换到gpu上执行(在不修改别人源码的情况下)。